
【go笔记】map结构的简介
Page content
go的hashtable是用map实现。
今天简单的整理了map的结构。
1.map的结构
hmap
在源码中, map的结构体是hmap, 它是hashmap的“缩写”。
先看看看源码是怎么解释的。
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
下面是每个字段的内容和值。
图片备用地址
 )
)
{kind=link}
bmap
其中可以看出保存map数据的是在【buckets unsafe.Pointer】
源码中的buckets pointer 是指向 bmap。
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
这里只有一个tophash字段,但是实际运行中bmap的结构会多几个字段。
看看这些源码的内容。
// https://github.com/golang/go/blob/go1.13.8/src/cmd/compile/internal/gc/reflect.go
func bmap(t *types.Type) *types.Type {
// 略...
field := make([]*types.Field, 0, 5)
field = append(field, makefield("topbits", arr))
// 略...
keys := makefield("keys", arr)
field = append(field, keys)
// 略...
elems := makefield("elems", arr)
field = append(field, elems)
// 略...
if int(elemtype.Align) > Widthptr || int(keytype.Align) > Widthptr {
field = append(field, makefield("pad", types.Types[TUINTPTR]))
}
// 略...
overflow := makefield("overflow", otyp)
field = append(field, overflow)
// 略...
}
从这里我们可以推断出,在执行的过程中bmap的结构是如下的。
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
这是每个字段含有的内容和值。
图片备用地址
 )
)
{kind=link}
这里需要解释一下。每个bucket(bmap)会存8调数据。
结构是头部会存一个uint8的tophash, 而且不是 key-value 的格式存纯数据。
是存连续的8个的key和连续的8个value。这样会节省空间。
mapextra
hamap里除了buckets(bmap)以外还有个extra *mapextra字段,
从字段名就能看出是是用于扩展的。
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
2.map的key的定位过程
下面继续看看Map是如何在这样的结构中保存数据和查询的。
图片备用地址
 )
)
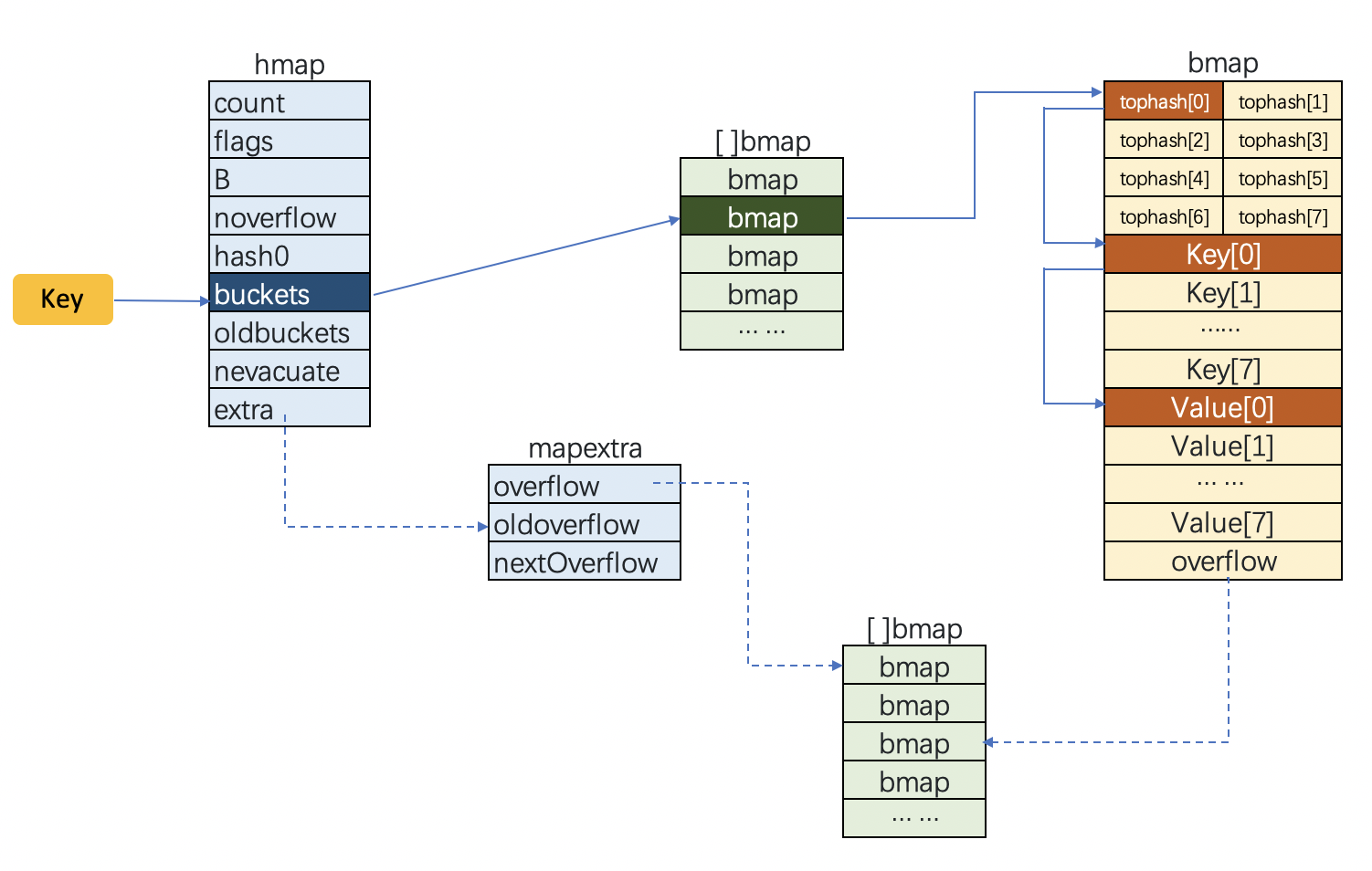{kind=link}
结合上图看看map查询key的定位过程的步骤:
- 先通过hash函数获取目标key的哈希,通过这个哈希值确定这个数据在哪个bucket(bmap)。
- 然后遍历bmap里的键(先对比前8位tophash,如果一致再去对比key)获取key的索引(找不到则返回空值)。
- 根据key的索引计算偏移量,获取到对应value。
- 如果bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找。
如上步骤是一个简化的过程,实际细节比这个复杂的多了。
如果想了解更详细的内容那只能是分析源代码了。
而且现在有很多大牛分享了这一个过程。
可以先看一下人家分析的内容在去看源代码,会节省的很多时间。
欢迎大家的意见和交流
email: li_mingxie@163.com