
【JVM】浅谈java编译和执行过程
上一篇【JVM】java大致的编译过程简单的解释了java编译执行过程。
这里稍微再详细点说明其编译和执行过程。
1. java代码到执行
java是高级语言(High-level programming language)。
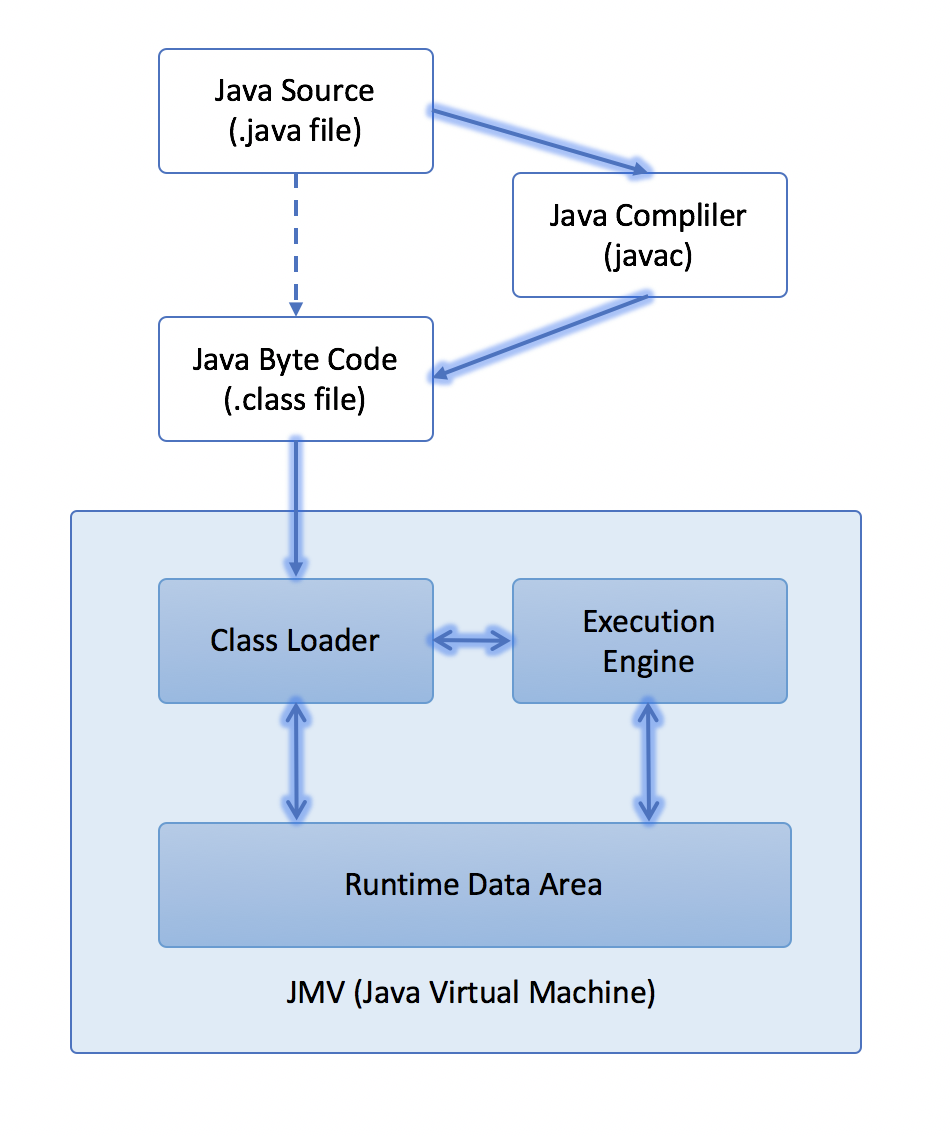
【执行】需【编译】成机器语言才能执行,如下所示。
java代码 => 编译 => 执行
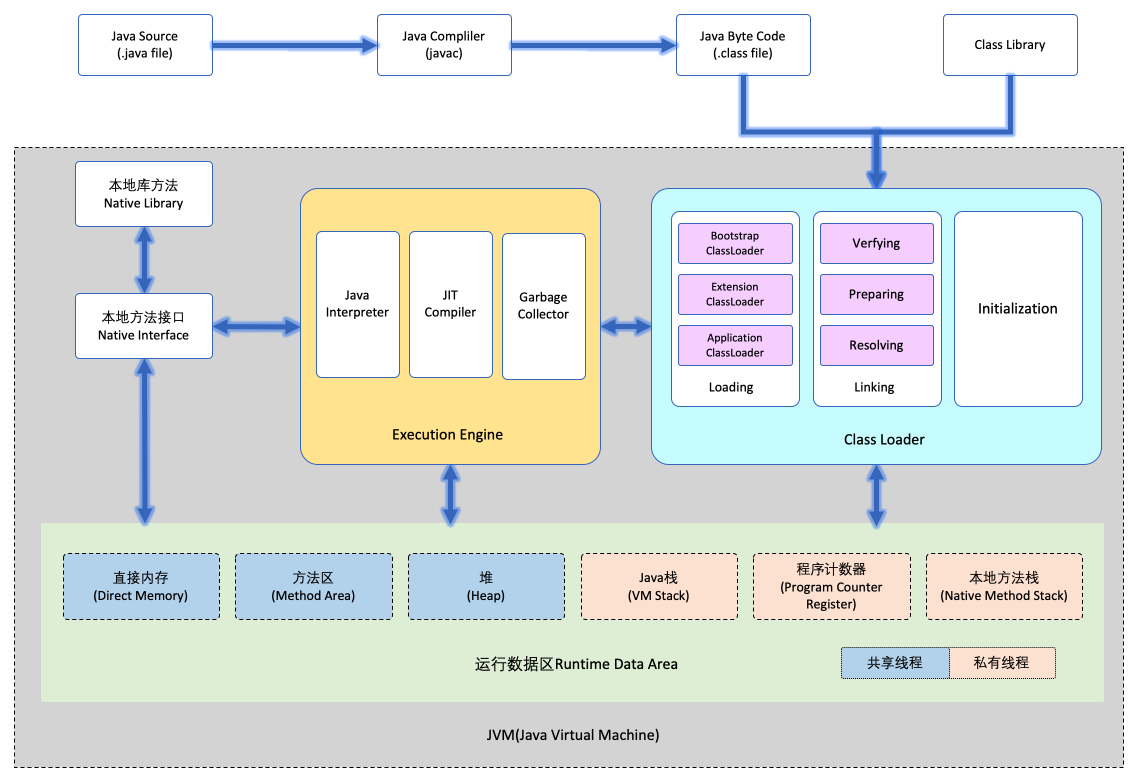
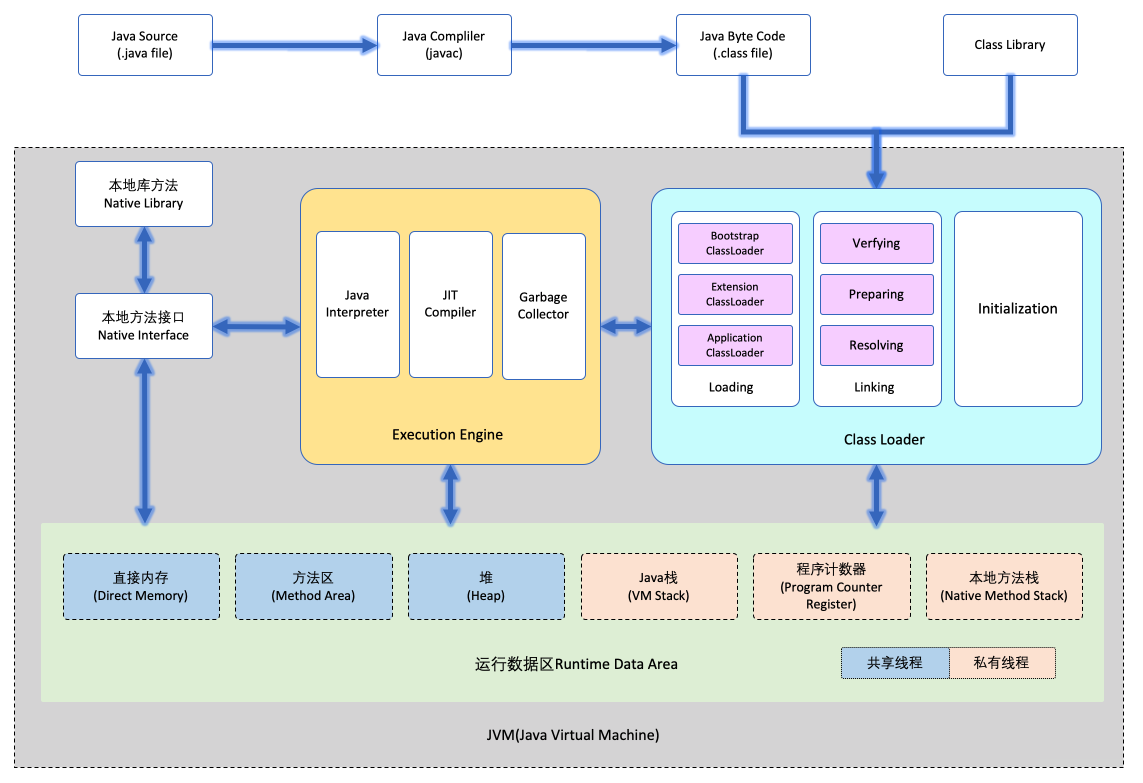
其中编译的内容我们需要用【class loader】加载到【JVM(Java Virtual Machine)】里才能执行。
把这些过程也加进去的话是如下的过程了。
java代码 => 编译 => 读取(class loader) => JVM环境 => 执行
我们在上面的基础上再详细的了解这些过程。
Java代码编译以后将会生成【.class文件】。(详细的javac编译过程可以参考【JVM】javac的编译过程)
类加载器(class loader)读取.class文件到JVM。
这时【执行引擎(execution engine)】把这些文件解析成【机器码(Binary Code)】,
存放到JVM的【运行数据区Runtime Data Area】后,执行程序。
这一过程可以如下图标是。

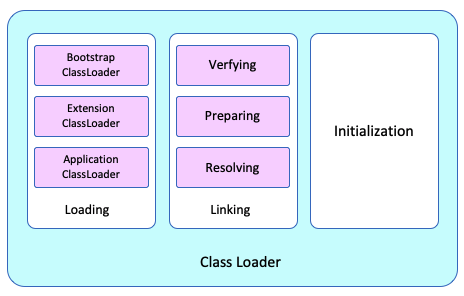
2. 类加载器Class Loader
.java文件编译后生成.class文件。
类加载器Class Loader的工作就是把.class文件读取到JVM中。
这过程类加载器Class Loader会做三件事情 1.加载 2.链接 3.初始化
2.1 加载Loading
一般情况下类加载器分3层结构。
2.1.1. 引导(启动)类加载器Bootstrap ClassLoader
- 最上层类。加载<JAVA_HOME>/jre/lib内容。用Native C编写。
2.1.2. 扩展类加载器Extension ClassLoader
- 加载<JAVA_HOME>/jre/lib/ext内容。用Java编写。
2.1.3. 应用程序类加载器Application ClassLoader
- 加载 -classpath(或 -cp)的内容。用Java编写。
这3层结构准守一下原则。
- Delegation Principle => 从上到下委派加载任务。
- Visibility Principle => 子类加载可以使用父类加载,相反是不可以。
- Uniqueness Principle => 子类加载时不会再次加载父类加载的内容。
2.2 链接Linking
加载完成以后,会做链接Linking。
链接也分3个步骤进行。
2.2.1. 验证Verify
- 确保加载的内容的正确性和安全性。
2.2.2. 准备Prepare
- 为类的静态变量分配内存,并设置默认初始值。
2.2.3. 解析Resolve
- 将常量池内的符号引用转换为直接引用的过程。
2.3 初始化
初始化是为类的静态变量赋予正确的初始值。
这个初始化不需要定义,是javac编译器自动收集类中的所有类变量的赋值和静态代码。
有父类先执行父类的初始化方法,再执行子类的初始化方法。

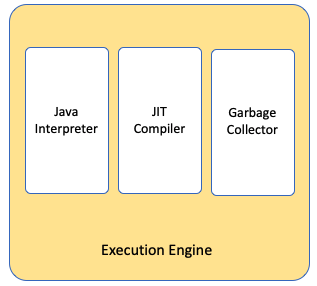
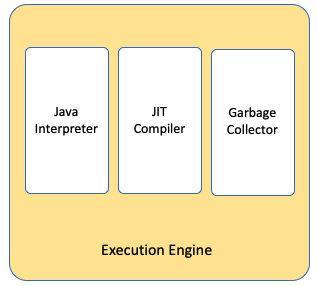
3.执行引擎Execution Engine
用于执行字节码或者本地方法。
执行的过程一般会用解释模式和JIT编译模式的混合模式。

3.1 解释器Interpreter
执行引擎会把类加载器读取过来的.class文件的字节码,
效验合法性和安全性后,边读取边执行。
3.2 JIT编译器JIT(just in time) Compiler
当解释模式运行的代码满足一定的条件以后,会编译到JVM的缓存中。
下一次执行的时候因为不需要在编译提高执行速度。
如果偶尔执行一次的代码或是只执行一次的话解释模式执行的速度会更快。
频繁的调用执行的代码的话,JIT编译模式下第一次执行速度会比较慢,后续会提高执行速度。
大部分情况下都会有混合模式。适用JIT编译模式的条件可以在不同的场景下需要做一些调整。
3.3 垃圾回收器Garbage Collector
执行引擎还跟垃圾回收器Garbage Collector有关。
一般情况下垃圾回收期会回收运行数据区Runtime Data Area的堆内存。
它会释放栈区里已经用完,找不到相对应地址的堆内存。
这些内存会分伊甸区,幸存区,老年区… 用一些算法来管理和清理回收内存。
这些细节会再后续的文章里再做分析讨论~
其实执行引擎是操控着这些编译和回收器,而不是它们属于执行引擎
图片备用地址
4. 运行数据区Runtime Data Area
为了执行程序,给JVM分配的内存空间。
可以分 共享线程区(堆区,方法区,直接内存区)和私有线程区(栈区,程序计数器,本地方法栈)
4.1 方法区Method Area
是各个线程共享的内存区域,它用于存储已被JVM加载的
类class,函数function,常量final variable,静态变量static variable,实例变量member variable
以及被即时编译器(JIT)编译后的代码都会存放在这里。
方法区有时被称为持久代(PermGen)。
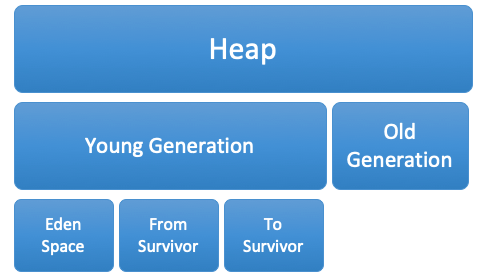
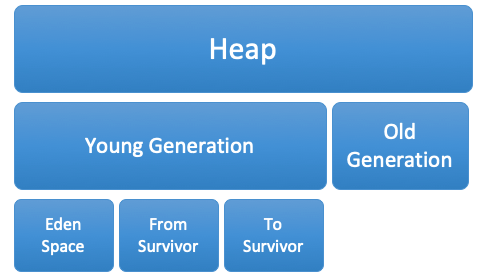
4.2 堆Heap
通过 New 创建的实例instance,队列等引用reference类型,Method Area的class才能声明在这里。
此内存区域就是存放对象实例,几乎所有的对象实例都在这里分配内存。
Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC堆”。
如果从内存回收的角度看,由于现在收集器基本都是采用的分代收集算法,
所以Java堆中还可以细分为:新生代和老年代;再细致一点的有Eden空间、From Survivor空间、To Survivor空间等。
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
4.3 直接内存(堆外内存)Direct Memory
在JDK1.4中新加入了NIO(New INput/Output)类,其实不完全的被JVM所控制。
它可以使用Native函数库直接分配堆外内存,避免堆和Native堆来回复制数据,提高性能。
4.4 栈Stack
它的生命周期与线程相同是一个临时储存空间。
存变量(boolean、byte、char、short、int、float、long、double),返回值,
对象引用类型(指向一条字节码指令的地址,其实体是存在堆Heap区域)
这些值遵守LIFO(Last In First Out) 当函数执行完成以后会删除掉。
4.5 PC寄存器Program Counter Register
每个线程thread都有一个。记录每个线程用哪个指令执行哪部分的内容,存储着现在执行中的JVM命令地址。
若该方法为native的,则PC寄存器中不存储任何信息。
Java多线程情况下,每个线程都有一个自己的PC,以便完成不同线程上下文环境的切换。
4.6 本地方法栈Native Method Stack
为了调用java以外的其它语言的方法分配的空间。
java调用C/C++方法是使用的stack领域就是这里。
其实直接内存不是完全属于JVM的运行数据区Runtime Data Area
图片备用地址

5. JVM(Java Virtual Machine)
把上面的就是全部都结合起来就是JVM的结构了。
如下图所示:
图片备用地址
6. 举例说明
一堆理论和概念会让人都晕的…^^;;
下面举一个例子,简单的说明一下这一过程。
import java.util.ArrayList;
import java.util.List;
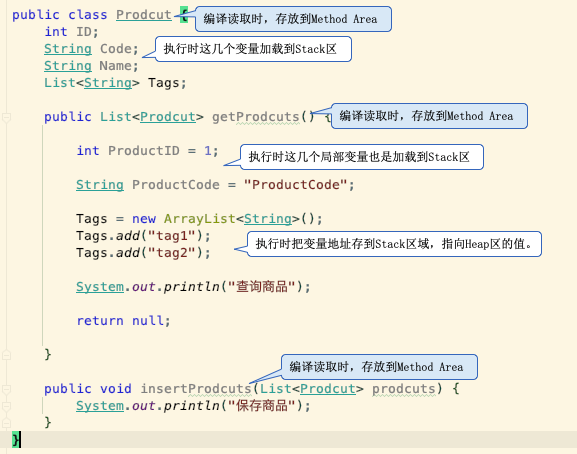
public class Prodcut {
int ID;
String Code;
String Name;
List<String> Tags;
public List<Prodcut> getProdcuts() {
int ProductID = 1;
String ProductCode = "ProductCode";
Tags = new ArrayList<String>();
Tags.add("tag1");
Tags.add("tag2");
System.out.println("查询商品");
return null;
}
public void insertProdcuts(List<Prodcut> prodcuts) {
System.out.println("保存商品");
}
}
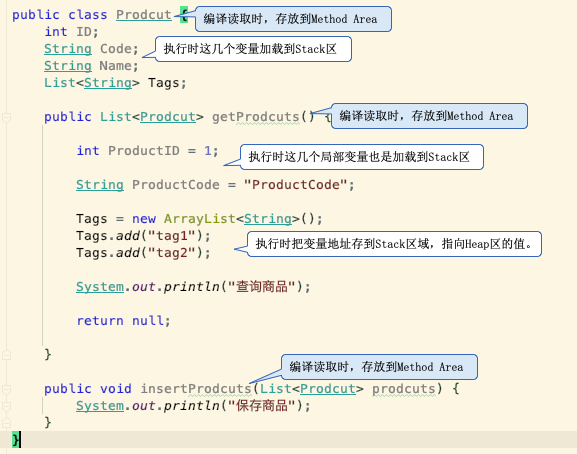
首先product.java通过java编译成product.class
然后Class Loader会把product.class和prodcut引用的Class Library加载到JVM环境。
这时Execution Engine做一些列验证和解析后(混合模式下,第一次不会直接走JIT编译)
把类信息和方法存放到Runtime Data Area的Method Area里。
当程序调用方法时,先把变量以及局部变量以及返回值加载到JVM的stack区域,
之后用New方式声明的实例或排列是存放到Heap区域,stack区域只保存对应的内存地址。
等方法结束后stack区域的值是跟着方法结束会一起清空,
但是heap区域的空间是需要等Garbage Collector来回收。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
7. 结语
我了解JVM的过程中发现它不可能用一遍文章说清楚。
只能说是了解了一点皮毛,每一块都有很多内容去了解。
比如加载程序,垃圾回收,编译过程等等… …
后续看看能不能每个模块都深入的去了解一下。
欢迎大家的意见和交流
email: li_mingxie@163.com