
【kafka笔记】kafka_文件存储(6)
这一篇整理了kafka的 文件存储 相关的内容。
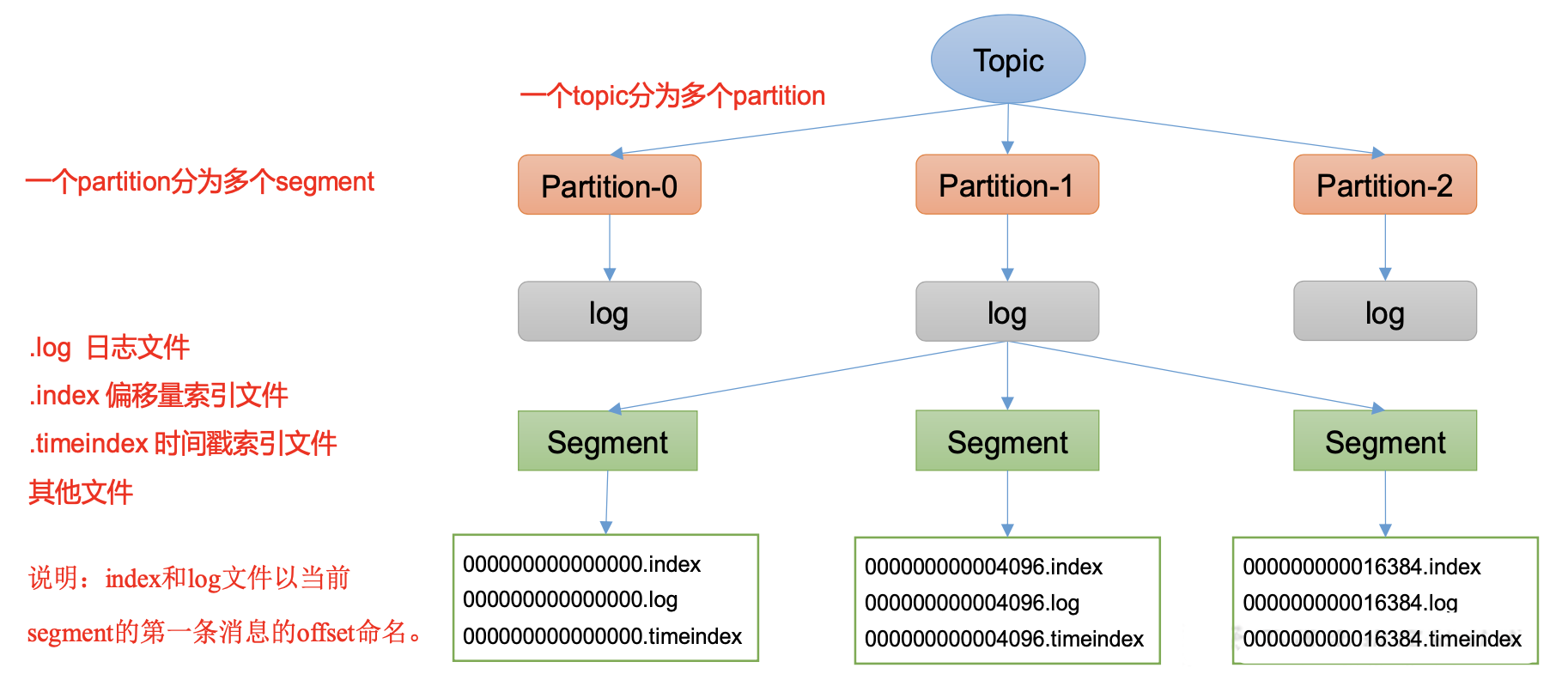
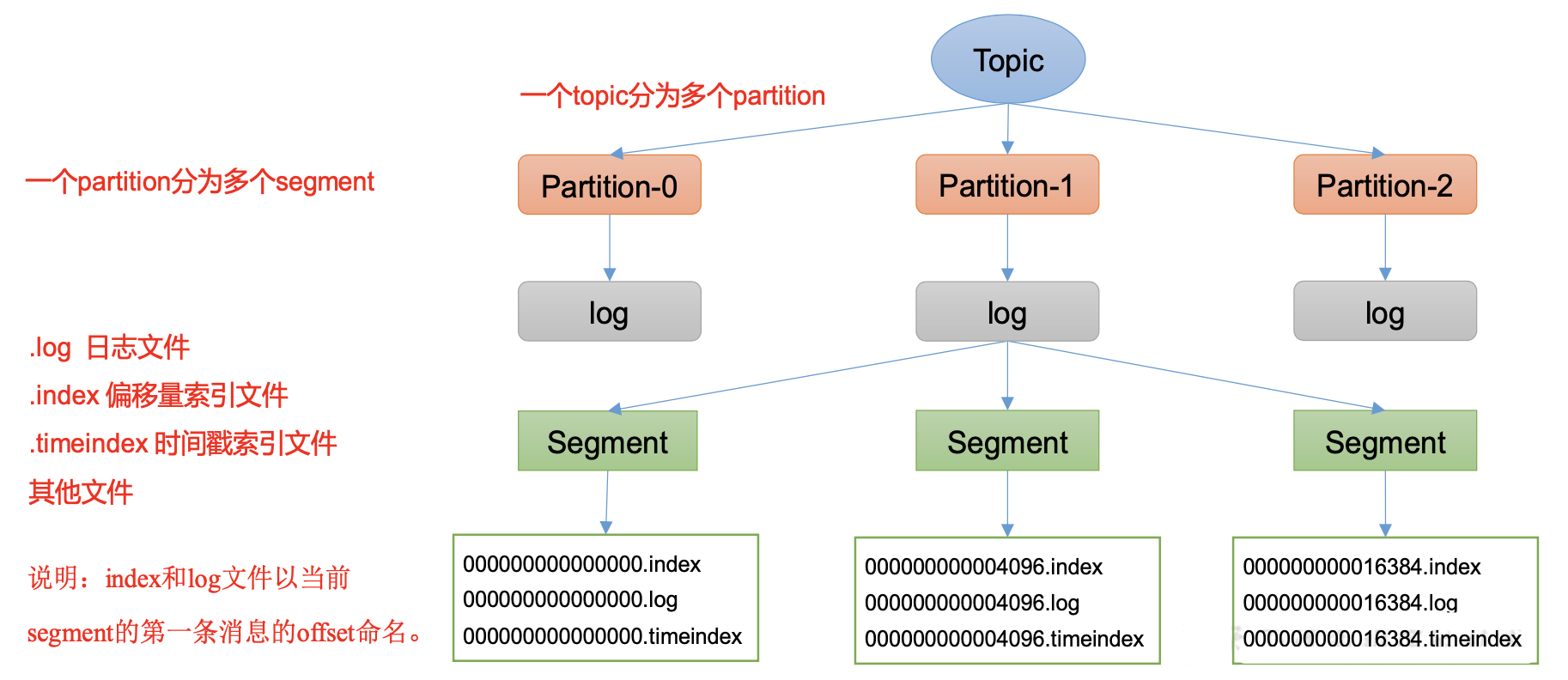
1.Topic 数据的存储
Topic是逻辑上的概念,而partition是物理上的概念,
每个partition对应于一个log文件,该log文件中存储的就是Producer生产的数据。
Producer生产的数据会被不断追加到该log文件末端,
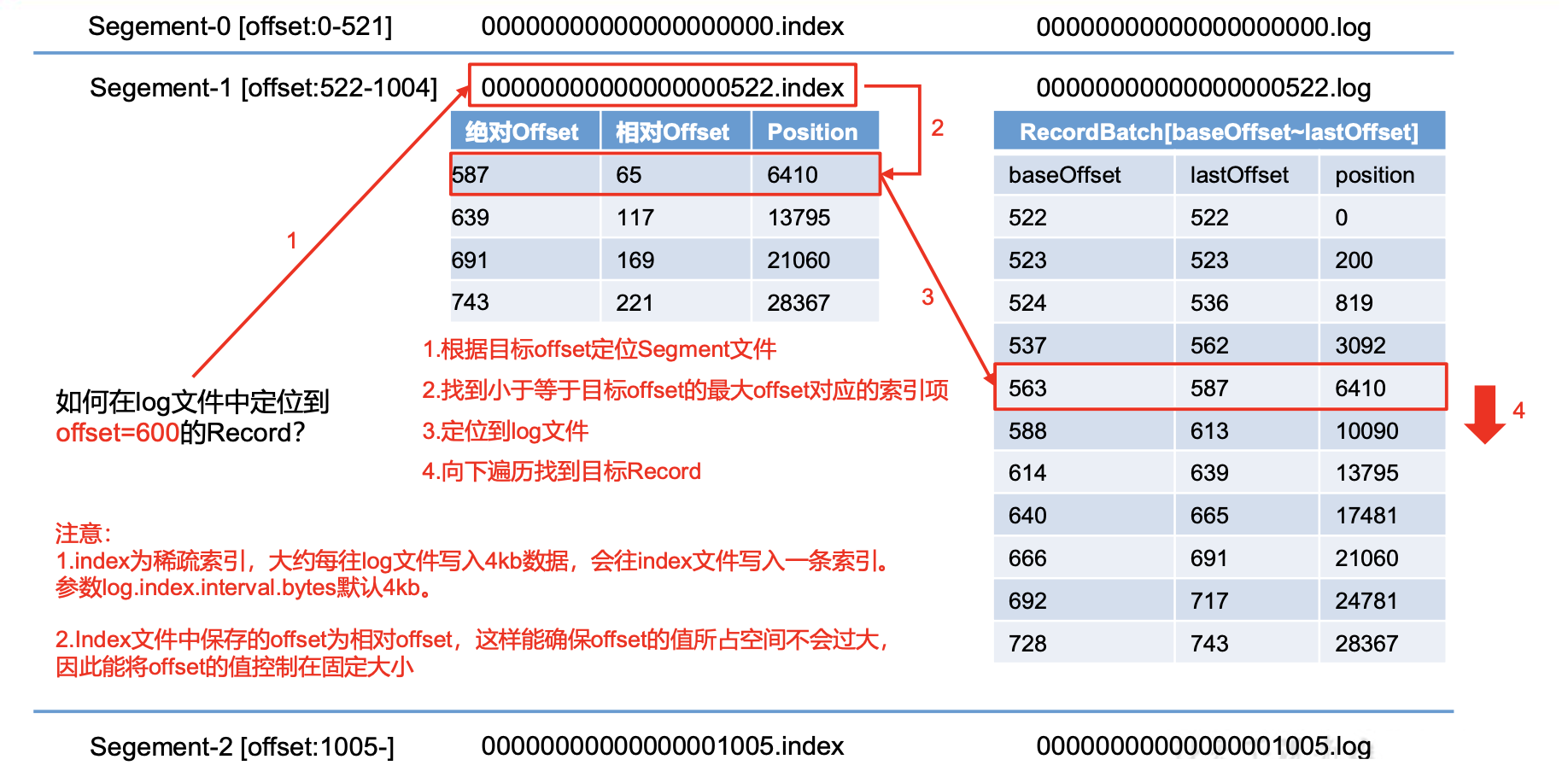
为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,
将每个partition分为多个segment。
每个segment包括:“.index”文件、“.log”文件和.timeindex等文件。
这些文件位于一个文件夹下,该 文件夹的命名规则为:topic名称+分区序号,例如:first-0。
2.Log文件和Index文件详解
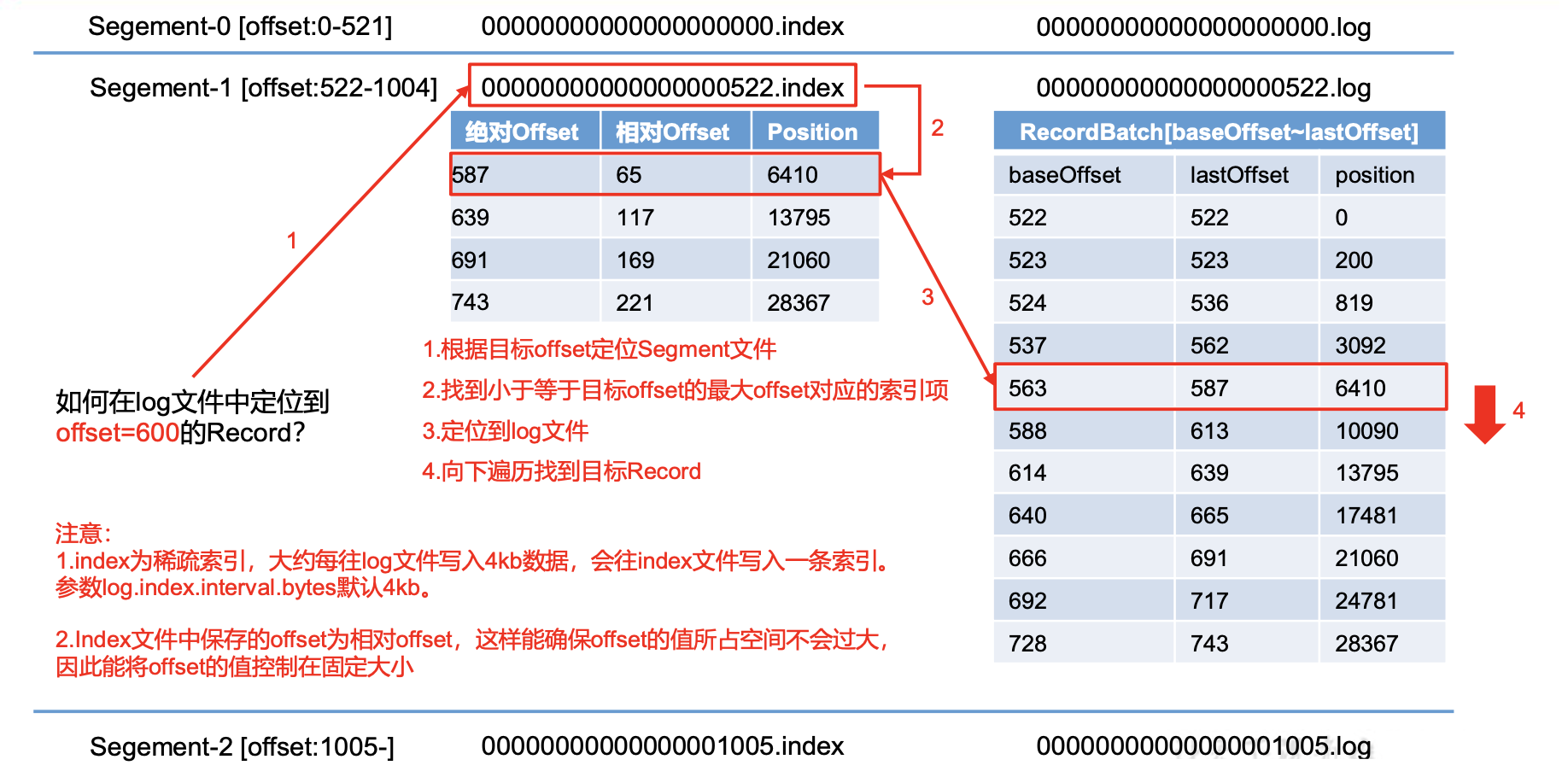
log.segment.bytes
Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。
log.index.interval.bytes
默认4kb,kafka里面每当写入了4kb 大小的日志(.log),
然后就往index文件里面记录一个索引。稀疏索引。
3.文件清理策略
Kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
- log.retention.hours,最低优先级小时,默认7天。
- log.retention.minutes,分钟。
- log.retention.ms,最高优先级毫秒。
- log.retention.check.interval.ms,负责设置检查周期,默认5分钟。
Kafka 中提供的日志清理策略有 delete 和 compact 两种。
3.1 delete 日志删除:将过期数据删除
- log.cleanup.policy = delete 所有数据启用删除策略
- 基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
- 基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。log.retention.bytes,默认等于-1,表示无穷大。
3.2 compact 日志压缩
compact日志压缩:对于相同key的不同value值,只保留最后一个版本。
- log.cleanup.policy = compact 所有数据启用压缩策略
这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,
通过这种压缩策略,整个消息 集里就保存了所有用户最新的资料。
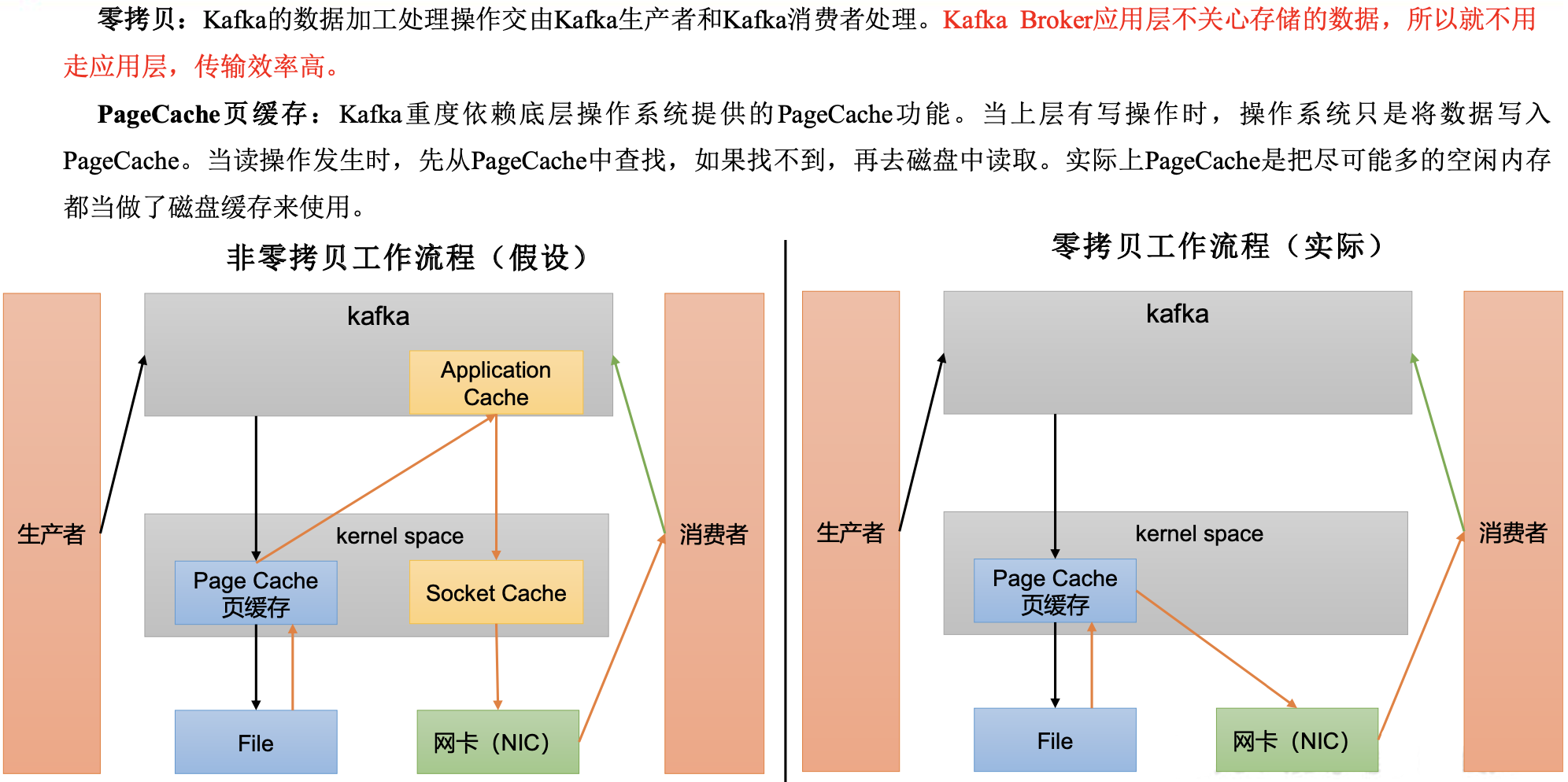
4.高效读写数据
- Kafka 本身是分布式集群,可以采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位要消费的数据
- 顺序写磁盘
Kafka 的 producer 生产数据,要写入到log 文件中,
写的过程是一直追加到文件末端, 为顺序写。 - 页缓存 + 零拷贝技术
{kind=link}
{kind=link}
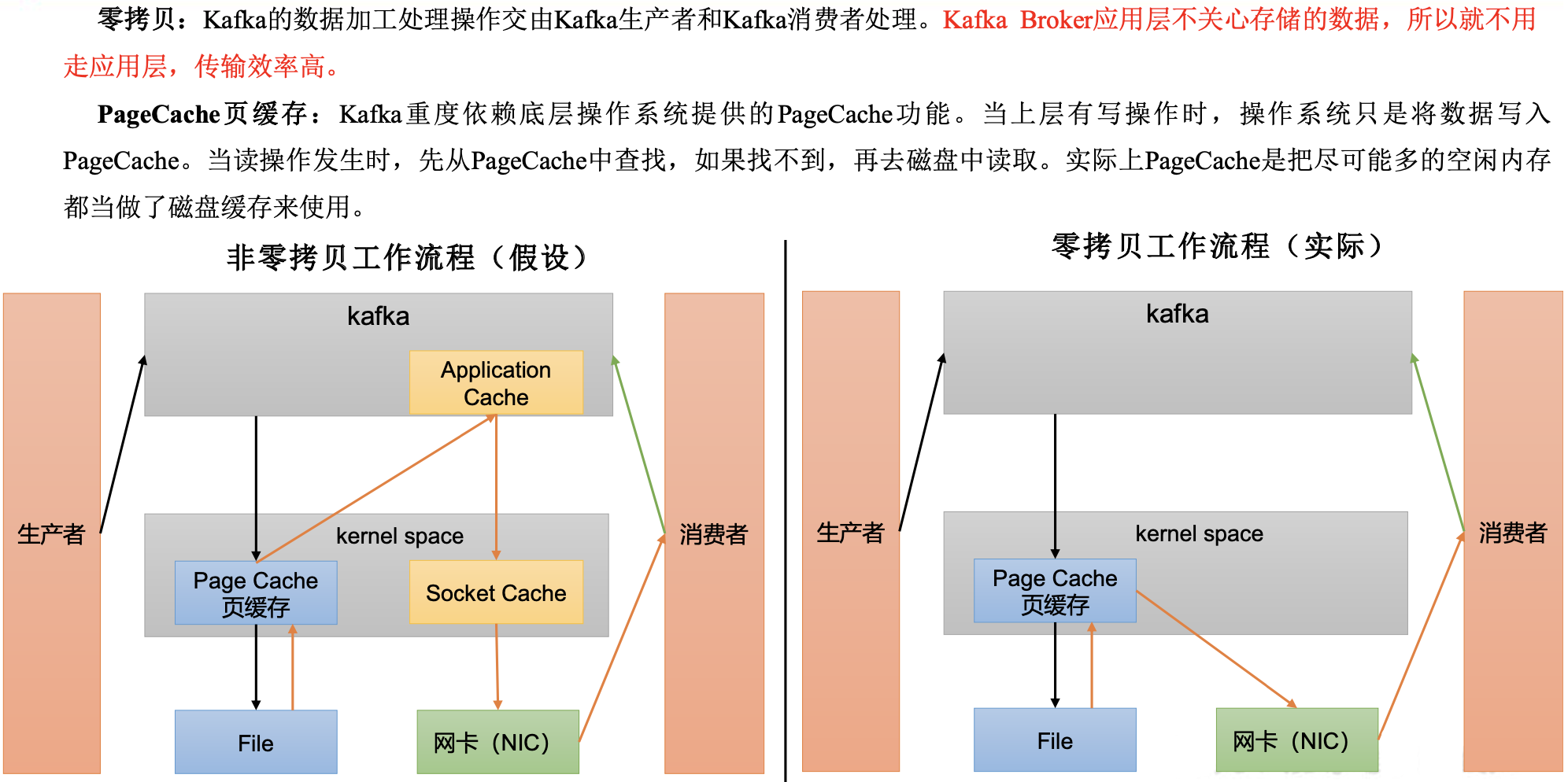{kind=link}
log.flush.interval.messages
强制页缓存刷写到磁盘的条数,默认是long的最大值,9223372036854775807。
一般不建议修改,交给系统自己管理。
log.flush.interval.ms
每隔多久,刷数据到磁盘,默认是null。一般不建议修改,交给系统自己管理。
欢迎大家的意见和交流
email: li_mingxie@163.com